Dependent and independent variables
The terms "dependent variable" and "independent variable" are used in similar but subtly different ways in mathematics and statistics as part of the standard terminology in those subjects. They are used to distinguish between two types of quantities being considered, separating them into those available at the start of a process and those being created by it, where the latter (dependent variables) are dependent on the former (independent variables).
Contents |
Simplified example
The independent variable is typically the variable representing the value being manipulated or changed and the dependent variable is the observed result of the independent variable being manipulated. For example concerning nutrition, the independent variable of daily vitamin C intake (how much vitamin C one consumes) can influence the dependent variable of life expectancy (the average age one attains). Over some period of time, scientists will control the vitamin C intake in a substantial group of people. One part of the group will be given a daily high dose of vitamin C, and the remainder will be given a placebo pill (so that they are unaware of not belonging to the first group) without vitamin C. The scientists will investigate if there is any statistically significant difference in the life span of the people who took the high dose and those who took the placebo (no dose). The goal is to see if the independent variable of high vitamin C dosage has a correlation with the dependent variable of people's life span. The designation independent/dependent is clear in this case, because if a correlation is found, it cannot be that life span has influenced vitamin C intake, but an influence in the other direction is possible.
Use in mathematics
In traditional calculus, a function is defined as a relation between two terms called variables because their values vary. Call the terms, for example, x and y. If every value of x is associated with exactly one value of y, then y is said to be a function of x. It is customary to use x for what is called the "independent variable," and y for what is called the "dependent variable" because its value depends on the value of x.[1] Therefore, 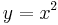 means that y, the dependent variable, is the square of x, the independent variable.[1][2]
means that y, the dependent variable, is the square of x, the independent variable.[1][2]
The most common way to denote a "function" is to replace y, the dependent variable, by 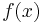 , where f is the first letter of the word "function." Thus,
, where f is the first letter of the word "function." Thus, 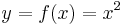 means that y, a dependent variable, a function of x, is the square of x. Also, in this form, the expression is called an "explicit" function of x, contrasted with
means that y, a dependent variable, a function of x, is the square of x. Also, in this form, the expression is called an "explicit" function of x, contrasted with 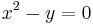 , which is called an "implicit" function.[1]
, which is called an "implicit" function.[1]
Use in statistics
Controlled experiments
In a statistics experiment, the dependent variable is the event studied and expected to change whenever the independent variable is altered.[2]
In the design of experiments, an independent variable's values are controlled or selected by the experimenter to determine its relationship to an observed phenomenon (i.e., the dependent variable). In such an experiment, an attempt is made to find evidence that the values of the independent variable determine the values of the dependent variable. The independent variable can be changed as required, and its values do not represent a problem requiring explanation in an analysis, but are taken simply as given. The dependent variable, on the other hand, usually cannot be directly controlled.
Controlled variables are also important to identify in experiments. They are the variables that are kept constant to prevent their influence on the effect of the independent variable on the dependent. Every experiment has a controlling variable, and it is necessary to not change it, or the results of the experiment won't be valid.
"Extraneous variables" are those that might affect the relationship between the independent and dependent variables. Extraneous variables are usually not theoretically interesting. They are measured in order for the experimenter to compensate for them. For example, an experimenter who wishes to measure the degree to which caffeine intake (the independent variable) influences explicit recall for a word list (the dependent variable) might also measure the participant's age (extraneous variable). She can then use these age data to control for the uninteresting effect of age, clarifying the relationship between caffeine and memory.
In summary:
- Independent variables answer the question "What do I change?"
- Dependent variables answer the question "What do I observe?"
- Controlled variables answer the question "What do I keep the same?"
- Extraneous variables answer the question "What uninteresting variables might mediate the effect of the IV on the DV?"
Alternative terminology in statistics
In statistics, the dependent/independent variable terminology is used more widely than just in relation to controlled experiments. For example the data analysis of two jointly varying quantities may involve treating each in turn as the dependent variable and the other as the independent variable. However, for general usage, the pair response variable and explanatory variable is preferable as quantities treated as "independent variables" are rarely statistically independent.[3][4]
Depending on the context, an independent variable is also known as a "predictor variable," "regressor," "controlled variable," "manipulated variable," "explanatory variable," "exposure variable," and/or "input variable."[5] A dependent variable is also known as a "response variable," "regressand," "measured variable," "observed variable," "responding variable," "explained variable," "outcome variable," "experimental variable," and/or "output variable."[6]
In addition, some special types of statistical analysis use terminology more relevant to the specific context. For example reliability theory uses the term exposure variable for what would otherwise be an explanatory or independent variable, and medical statistics may use the term risk factor.
Examples
- If one were to measure the influence of different quantities of fertilizer on plant growth, the independent variable would be the amount of fertilizer used (the changing factor of the experiment). The dependent variables would be the growth in height and/or mass of the plant (the factors that are influenced in the experiment) and the controlled variables would be the type of plant, the type of fertilizer, the amount of sunlight the plant gets, the size of the pots, etc. (the factors that would otherwise influence the dependent variable if they were not controlled).
- In a study of how different doses of a drug affect the severity of symptoms, a researcher could compare the frequency and intensity of symptoms (the dependent variables) when different doses (the independent variable) are administered, and attempt to draw a conclusion.
- In measuring the acceleration of a vehicle, time is usually the independent variable, while speed is the dependent variable. This is because when taking measurements, times are usually predetermined, and the resulting speed of the vehicle is recorded at those times. As far as the experiment is concerned, the speed is dependent on the time. Since the decision is made to measure the speed at certain times, time is the independent variable.
- In measuring the amount of color removed from beetroot samples at different temperatures, the dependent variable would be the amount of pigment removed, since it is depending on the temperature (which is the independent variable).
- In sociology, in measuring the effect of education on income or wealth, the dependent variable could be a level of income or wealth measured in monetary units (United States Dollars for example), and an independent variable could be the education level of the individual(s) who compose(s) the household (i.e. academic degrees).
Manipulated versus subject variables
Up to this point, the term independent variable has meant some factors that are manipulated directly by the researcher. An experiment compares one condition created by and under the control of the experimenter with another. In many studies, however, comparisons are also made between groups of people who differ from each other in ways other than those manufactured by the person designing the study. These comparisons are made between factors that are referred to variously as:
- Ex post facto variables
- Natural group variables
- Non-manipulated variables
- Subject variables
They refer to already existing characters of the subject participating in the study, such as gender, age, intelligence, physical or psychiatric disorder, and any personality attribute and any personality attribute one can name. When using subject variables in a study, the researcher cannot manipulate them directly but must select subjects for the different conditions by virtue of the characteristics they already have.
For more information, see Quasi-experiment.
References
- ^ a b c Thompson, S.P; Gardner, M; Calculus Made Easy. 1998. Page 10-11. ISBN 0312185480.
- ^ a b Random House Webster's Unabridged Dictionary. Random House, Inc. 2001. Page 534, 971. ISBN 0375425667.
- ^ Everitt, B.S. (2002) Cambridge Dictionary of Statistics, CUP. ISBN 0-521-81099-x
- ^ Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 0-19-920613-9
- ^ Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 0-19-920613-9 (entries for "independent variable" and "regression")
- ^ Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 0-19-920613-9 (entry for "regression")